
Listen to this article:
A version of this article was first published on AWS for Industries on April 4, 2022. Since that time, AWS started using Loka's version of Cromwell.
Chronic kidney disease (CKD) affects 780 million people globally—one in every ten. To discover novel therapeutics to help this underserved patient population, most of which has no good treatment options, Goldfinch Bio built a Structural Variant Analysis capability on AWS to help find a cure for CKD.
Few data sets are available to commercial organizations in the public domain, so Goldfinch invested significant financial and labor resources into whole-genome sequencing on thousands of patients with kidney disease. Previously, much of the analysis performed on these data sets relied solely on the identification of single nucleotide polymorphisms (SNPs, single base pair changes in the DNA). With the recent development of Broad’s GATK-SV pipeline, the performance of Amazon FSx for Lustre and the help of AWS Advanced Consulting Partner Loka, Goldfinch Bio utilized its existing sequencing data to identify structural variants that can lead to new medicines for patients suffering from chronic kidney disease. As a result, the analytical value of Goldfinch’s existing genomic data increased overnight.
Goldfinch Bio believes that analysis of structural variation is a fundamental piece of the genomic puzzle, with the potential to provide a missing link between genomic variation and kidney disease.
Solution Overview
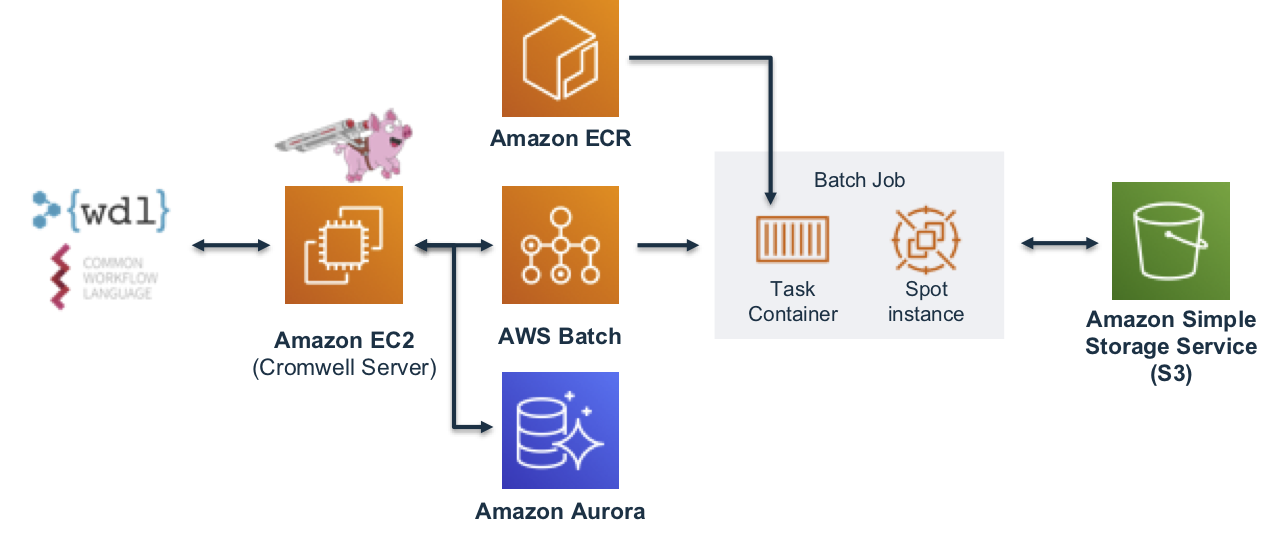
The GATK-SV pipeline was developed by the Broad Institute, written in Workflow Definition Language (WDL) and orchestrated using the Cromwell engine. The team knew that the large intermediate and reference files required by the pipeline would be best served with a high-performance file system. They also needed a solutions integrator with deep cloud experience to tie it all together in a reproducible way so the scientists at Goldfinch could use it on their own.
Pipeline and HPC Orchestration: We chose Broad’s GATK-SV pipeline and AWS’ own Genomics Workflows on AWS for orchestration. The pipeline was developed to call, filter and integrate structural variants across large cohorts using short-read sequencing data. This is particularly important because it can leverage existing data, as opposed to alternative sequencing approaches that would require a significant investment. The Genomics Workflows on AWS reference architecture makes it easy to stand up Cromwell environments on AWS Batch.
This is particularly important because it can leverage existing data, as opposed to alternative sequencing approaches that would require a significant investment.
High-Speed Storage: GATK-SV is a complex and resource-intensive pipeline that runs almost 12.5k+ batch jobs and generates millions of files/objects along the way (stats as per execution for 156 1K-Genome samples). This pipeline was initially ported to work with S3 which previously pulled down/localized the required files, performed the task and then uploaded the output/staging files back to S3 for each Batch job. This was a major performance bottleneck which led us to explore other scalable and high-performance options.
Amazon FSx for Lustre was a great fit for this scenario due to its scalability, performance, provisioning, mounting capabilities and wide range of file system types like SSD, HDD and Scratch along with customizable throughput ranges. Additionally, compared to alternatives, the operating cost is also low.
We then integrated FSx with AWS Batch and Cromwell (workflow orchestration engine) to handle FSx along with the infrastructure templates and started seeing the performance boost right away. As evidenced from the benchmark table provided later in this post, the execution time dropped drastically from 3+ days to 1.3 days, which not only saves on the effort but also helps reduce overall cost of EC2 instances used and enables quick analysis of the results. We now have functionality to use either FSx or S3 depending on the use case and performance/cost requirements.
The execution time dropped drastically from 3+ days to 1.3 days, which not only saves on the effort but also helps reduce overall cost of EC2 instances used.
Deeply Qualified Solutions Integrator: Modifying the pipeline and storage required not only changing the code contained within WDL files, but also Cromwell, the workflow orchestration engine and the AWS Infrastructure Templates. Loka is an Advanced Tier partner with a deep understanding of both cloud and scientific workflow definitions, as well as strong familiarity with storage. Our specialized knowledge of HPC, AWS Batch, open-source packages, open data sets and processes like parallelization (which enables thousands of jobs to run simultaneously) delivered Goldfinch best of breed solutions faster than they could’ve achieved on their own.
How to Deploy GATK-SV in Your Own AWS Environment
The following steps will help you reproduce our architecture in your own AWS environment. Note that these steps offer high-level guidance. You can find more detailed deployment instructions on GitHub.
Step 1) Deploy the Genomics Workflows on AWS
- Open and follow the Genomics Workflows on AWS deployment guide
- When deploying the Genomics Workflow Core stack, supply the following:
1. For CreateFSx, choose Yes
2. For Cromwell FSxStorageType, choose Scratch
3. For FSxStorageVolumeSize, type 24000 (MELT) or 16800 (without MELT) - When deploying the Cromwell Resources stack, supply the following:
1. For FSxFileSystemID, supply the id from the gwfcore template output tab
2. For FSxFileSystemMount, supply the id from the gwfcore template output tab
3. For FSxSecurityGroupId, supply the id from the gwfcore template output tab
Step 2) Deploy GATK-SV onto your Cromwell host
We built a small CloudFormation template that deploys an AWS SSM command document to run against your Cromwell server. This command document clones the Broad’s GATK-SV repo and makes some tweaks to the Cromwell config files to support connecting with Amazon FSx.
- Deploy the SSM command:
wget https://github.com/goldfinchbio/aws-gatk-sv/blob/master/templates/cf_ssm_document_setup.yaml
aws cloudformation deploy –stack-name "gatk-sv-ssm-deploy" –template cf_ssm_document_setup.yaml –capabilities CAPABILITY_IAM - Open the AWS Systems Manager Console
- In the navigation pane, under Documents, choose “Owned by me”
- Search for gatk-sv-ssm-deploy in the search bar
- Click the Execute Automation button
1. For Instance Id, choose the listed Cromwell server
2. For S3OrFSXPath, use the mount name in the Stack Output from Step 1
Step 3) Execute and monitor the pipeline
- Start a shell session on the Cromwell server
- Run cromshell submit commands
1. The below will run the pipeline for 156 (1000 Genomes) samples.
cromshell submit /home/ec2-user/gatk-sv/gatk_run/wdl/GATKSVPipelineBatch.wdl /home/ec2-user/gatk-sv/gatk_run/aws_GATKSVPipelineBatch.json /home/ec2-user/gatk-sv/gatk_run/opts.json /home/ec2-user/gatk-sv/gatk_run/wdl/dep.zip - Monitor pipeline
1. cromwell status
Alternatively, consider usingget_batch_status.py script to gather the information from AWS Batch and CloudWatch logs to give a consolidated and better view of the resources and job completion details along with higher level and module level summaries.

Measuring Quality, Performance and Cost
Quality
Using a trial dataset that contains 156 individuals from the 1000Genomes project, we showed concordance of our results with the original pipeline.
Concordance between our pipeline and Broad’s published standard

The number of various structural variants such as deletions (DEL) or duplications (DUP) is consistent between the four conditions (see figure above). We performed two FSx runs with and without the proprietary structural variant caller MELT which resulted in a reduction of insertions (INS, 19,001 vs 10,091) as expected.
To further investigate consistencies between pipelines, we compared the exact position in the genome where structural variants were detected by our three callsets (S3 and FSx) and the original pipeline (Broad). This evaluation is stringent because the false positive/negative class would also include structural variants that are offset by only a few base pairs. Comparing Amazon FSx (with MELT) with the Broad gold standard we reached a precision of 0.95 and a recall/sensitivity of 0.92. Comparing S3 and FSx (without MELT) run resulted in a precision of 0.95 and recall/sensitivity of 0.96 when using S3 as the reference dataset.
Performance and Cost
Our optimizations decreased runtime and reduced our overall costs by a third. Below is a table describing the duration it took to complete each module on Amazon FSx and S3 with and without MELT.
GATK-SV module runtimes and costs with Amazon FSx and MELT

Conclusion
By analyzing structural variation in short-read sequencing data and studying different types of genomic rearrangements, we can uncover new insights and better understand certain diseases. This novel process helps us gain greater value out of existing data.
Resources such as the UK Biobank and AllofUS increase the number of population scale whole genome sequencing datasets which lend themselves to structural variant research. While this is a rapidly evolving methodology, it can be overwhelming for researchers with limited technical resources to leverage a pipeline like GATK-SV.
It is our hope that novel drug targets can be discovered to help patients in need of therapeutic intervention. By releasing the customizations and optimizations of this pipeline as an open-source reference architecture, the community can leverage these improvements on additional data to lead to novel scientific insights.
Want to dive deeper?
- Check out the detailed deployment guide on our GATK-SV github repo.
- Contact AWS Advanced Consulting Partner Loka for GATK-SV support or customization in your own environment.
- Listen to Episode #14 of the AWS Health Innovation podcast featuring Adam Tebbe of Goldfinch Biopharma and Bobby Mukherjee, Founder and CEO of Loka on iTunes , Spotify or Stitcher.





%20(1).webp)

{kind=link}